

 会员登录
会员登录
从文档互联到价值互联——Web 3的前世今生
Web 的本质是 Serendipity.
Web 3.0 的本质是 Accountability.
2021 年 7月 10 日,在由中国科学院文献情报中心主办的第二届“数据智能与知识服务”学术研讨会上,来自国际知名学者与业界领袖围绕 “数据智能与知识服务” 为核心主题,带来了一场豪华的学术盛宴。会上,鲍捷发表了主题为《从文档互联到价值互联——Web 3的前世今生》的演讲,对 Web 领域进行了一个宏观的回顾。
以下为演讲实录:
今天的演讲内容主要是对 Web 3.0 领域的一个宏观回顾。《Data Intelligence》 (数据智能) 杂志脱胎于之前语义网的研究,语义网是 2001 年成立的一个学科,今年正好是 20 年。在这 20 年里我们经历了很多高光时刻,也经历了领域的低谷,所以想借此机会将这 20 年时间里所经历的事情和大家做一个回顾,也看一下未来有哪些点是更有价值的。
相信今天讲的内容不完全都是共识,因为有一些是我个人的看法,可能会有争议,但我也相信有价值的问题对于领域来说更重要。
Web 是“缘”
Web 技术在 1991 年正式上线。1989 年有了 Tim Berners-Lee 第一个版本的 Web 建议书。1991 年才真正有世界上第一个万维网网站,到今年是整整 30 年时间。
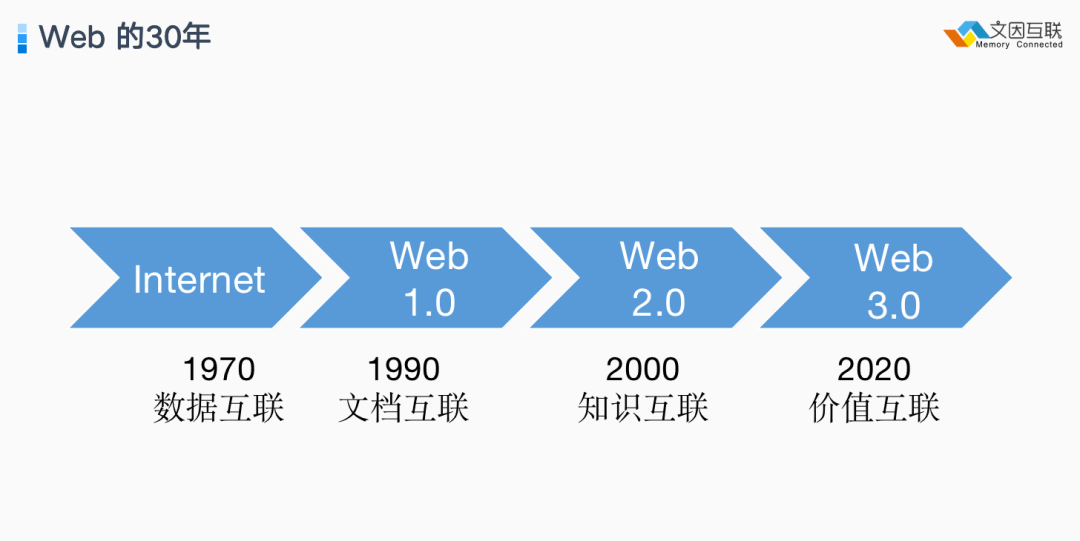
我们可以把 Web 的发展分为三个阶段:第一个阶段是刚开始的十年,称为 Web 1.0 ,主要是文档互联时代,就是把各种各样在线的网页互联起来;第二个阶段是从 2000 年至 2020 年,可以称之为 Web 2.0 ,主要是如何把包括人在内的各种商业实体在线上重新连接起来的过程,可以称为知识互联时代;第三个阶段是从 2020 年开始,称为 Web 3.0 ,也就是价值互联阶段。今天主要来解释一下:什么是价值互联以及为什么它必然是 Web 发展的未来。
当提到 Web 时就不得不提到 Web 之父——Tim Berners-Lee,也是2016年图灵奖得主。他在 30 年前提出了 Web ,并提出一个愿景:This is for everyone(要让全世界所有人能够自由去访问信息)。

为了达到这一愿景,我们需要一个开放、有活力的信息架构。经常会有人把 Internet(因特网) 和 Web 混为一谈,其实并不然,因为 Web 只是因特网的一个应用。因特网还有许许多多其他的应用,比如电子邮件、FTP(文件传输)、聊天(及时通信)、新闻组、语音传输(VoIP)、物联网等等,并不仅仅是 Web。
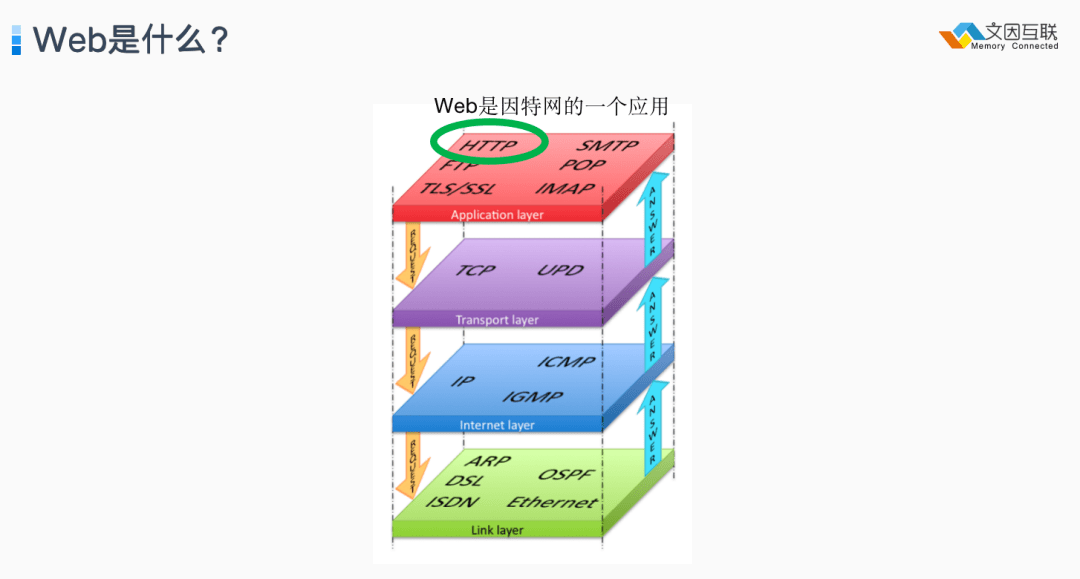
这里需要讨论一个非常核心的问题,为什么有了 Internet,我们还需要 Web?Web,不管是第一代还是现在的第三代 Web, 真正的核心本质是什么?到底是什么让 Web 超越了 Internet 上所有其他的应用,成为最成功的一个,甚至“吃”掉了很多其他应用?在我看来,这个特质就是“Serendipity”。
这个英文单词的含义是“finding interesting or valuable things by chance”,被翻译为“意外之喜”或“机缘巧合”。我觉得翻译成“缘”可能最合适。世间有许多本来没有发生关系的事物,一个人想发现另一个人,一个物要配合另一个物,都需要“缘”。我们构成家庭,建立市场交换,遇到远方的人扩大了自己的知识,这些都使我们更加富足、更加睿智。但是在有 Web 之前,产生这些“缘”成本过高,大部分是需要规划的,是不足够自由的。
Web 则是提供了一个自由的平台,让世界上的“资源”(resources),能够在没有中央事前规划的前提下,相互发现,产生连接,产生“缘”,“Serendipity”。网恋,如电影“You've Got Mail” (1998) 或小说“第一次亲密接触”(1998) 的故事,是“缘”;电子商务,你买到你心爱的东西,是“缘”;苦思冥想一个问题不得解,网上一通搜索发现启发,是“缘”;看到一条微博忍不住哈哈一笑,分享给好友,也是“缘”。
如果没有自由,就不会有“缘”。Web 的生命力就在于自由,它的成功就和市场经济一样,在于分散化的决策,从而建立分工和协作。这样的分布式系统,才是健壮的,才是可扩展的,才是有持久生命力的。倘若 Web 被强行集中化了,就不再有“Serendipity”,就再难以自发产生有价值的连接,这样的 Web,就会成为行尸走肉。在这个意义上,“This is for everyone”才是 Web的核心愿景,也是 Web 的成功原因。Tim Berners-Lee 一直在捍卫 Web,当 Web 偏离了这个愿景,他就会如持剑的勇士一般,去斗一斗那些破坏 Web 的恶龙。
Web 的本质是“缘”,是“Serendipity”,是信息的自由市场经济。
Web 1.0 : 文档的互联
1999 年 Tim Berners-Lee 在 Web 临近第一个十年时,写了一本《编织万维网》(Weaving the Web),在这本书里他阐述了当年发明 Web 的相关背景知识和初始愿景。

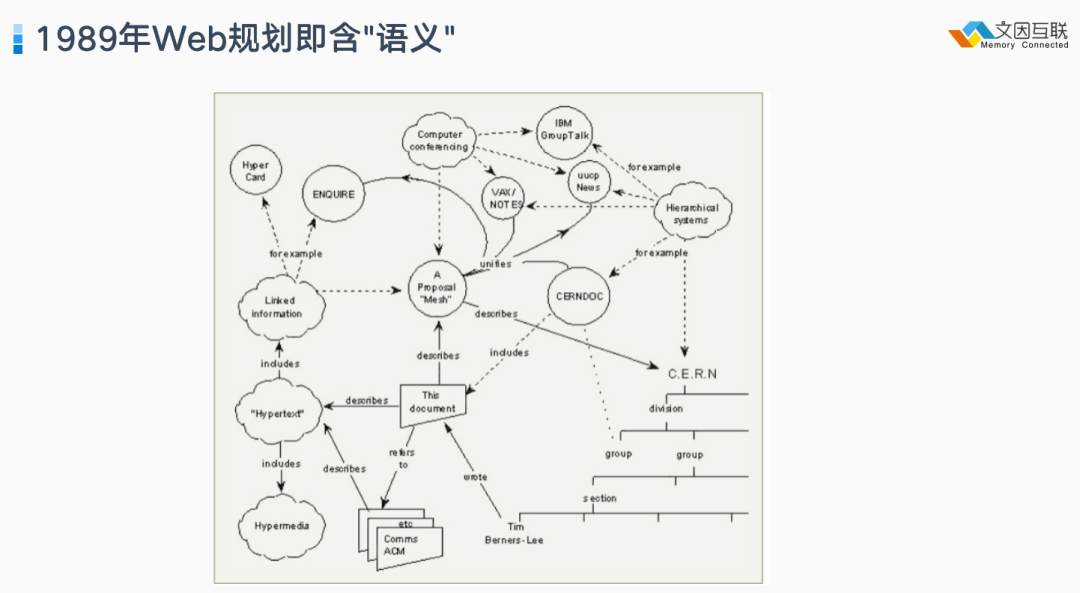
早在 1980 年就已经有 Web 第一个版本。Tim Berners-Lee 在 Web 最早的规划里面给出这样一张图,今天来看这张图大家会说这就是知识图谱嘛,其实知识图谱之所以是 Web 发展的一个延续并不是偶然,因为在 1989 年初始的 Web 规划里就已经包含了这样的语义。
Tim Berners-Lee 在《编织万维网》这本书里刻画了一个宏伟愿景,我们可以把这个愿景拆分为三个阶段:第一个阶段是 Internet + 超文本,这是我们所熟知的第一个版本的 Web 1.0,是文档的互联;Web 的第二个阶段是 Web + 元数据( Metadata ),我们在本世纪初时称它为 “Semantic Web”,现在称为知识图谱,本质上就是知识的互联。
如今进入到一个新的阶段,就是如何把知识和人连接在一起,特别是知识本身不仅只是一些信息,它更多是承载着各种各样的商业价值和社会价值。所以这个阶段在语义网之上加入了更多的东西(探索引擎,也可能是其他东西),它的核心本质就是如何让价值在人与人之间、组织与组织之间进行高速流动,从而产生价值网络或资产网络。其实在 Web 早期时(30年前)Tim Berners-Lee 就已经有了这种愿景。

Web 是在 1994 年开始真正腾飞的。Amazon 就成立于 1994年。那时候也出现了最早的浏览器。Tim Berners-Lee 在 1991年那个版本只提供了一种 line-mode 浏览器。1992年一个中国人 Pei Wei 写出了世界上第一个图形化的浏览器 ViolaWWW。1993年出现了 Mosaic 和 Lynx。Mosaic 后来成为了网景公司的 Navigator。Lynx 是一个纯字符的浏览器,我 2001 年到美国的时候还在用。1994年出现 Opera ,1995 年微软推出 IE,之后 Web 就彻底普及了。

之后 5 年内 Web 成功实现了文档互联,比如各种各样的个人主页、商家静态的页面,在 2000 年就已经能够互连在一起。这时候的 Web 被称为 read-only Web,因为缺少方便的在线编辑工具。那时候甚至连在线表单(web form)都不是很常见。页面都需要离线编辑好后再 FTP到服务器上。所以信息是以非交互的方式互联的,缺少实时的互动或者双向的互动。那时候这种互动反而不发生在 Web上,而是在电子邮件里或者网络论坛(BBS,用 telnet 协议)上——当然后来电子邮件和论坛都被 Web “吃”掉了,今天的网民可能已经无法分清这些应用之间曾经的区别。
在这个意义上,Web 1.0是“文档互联”,互联的是静态的文档。尽管简陋,但是在当时已经产生了巨大的商业意义。它让信息发现的难度大大降低了,而信息的边界就是市场的边界。

这时有了 Web 的第一次泡沫,随便什么想法连个PPT都没有都能融到资。1995年,网景(Netscape)只用16个月就上了市,创造了30亿美元财富,一下子激发了疯狂的投资高潮。Yahoo是1994年成立的,eBay是1995年,Google和Paypal是1998年,他们和 AOL、MSN等活到第二季。但是 Pets.com、Webvan、Boo.com、Worldcom 等当时的明星都没有熬过这个“dot-com泡沫”。到2000年这个泡沫破了,不过留下了全美光纤网络和数以万计的人才,为 Web 的第二个版本的腾飞做好了准备。
Web 2.0 : 社会的互联
在 21 世纪的第一个十年中,静态 Web 被改造为动态 Web ,单向信息发布被改造成双向信息发布,从而进入到 Social Network 的时代。表单(Forms)技术其实是 Pei Wei 在1992年前后就发明了,但是它广泛应用是到“2.0”时代,这时人们不需要到服务器上编辑文档也可以发布内容了,也不需要再懂FTP,内容发布的成本大大下降了。Web 2.0因此也被称为read-write Web。
这进一步提升了 Web 的“serendipity”,让没有任何技术背景的人也可以参与到资源发布中来。这使得原来“没有意义”的内容也得以发布了,比如一张随手拍的照片、一个偶然的念头、一个小地方的逸事,这些东西,后来变成了 Facebook 、Twitter、Wikipedia。普通人得以互联,而不仅仅是“文档”得以互联。 Clay Shirky 在2008年写了本书,《人人时代》Here Comes Everybody,总结在 Web 2.0下,组织如何自发地形成。
之前大家会称“Social Network”为社交网络,但在我看来 Social 一词与其翻译成“社交”不如翻译成“社会”,因为它本质上所反映的是如何把人类社会中各种各样的主体映射到网上的过程。人是其中一个很重要的点,但不是全部,也包括很多其他各种点(比如商业、信息等)。

现在又过了快 20 年时间,回过头来看 Web 2.0 的本质就是实体(Entity)的互联,也就是把线上信息实体和线下物理实体连接在一起。同时我们也建立起这些实体间的关系(Relation),而这些关系本质上就是知识, Entity 和 Relation 加在一起就是知识图谱,这是 Web 的第二个十年。

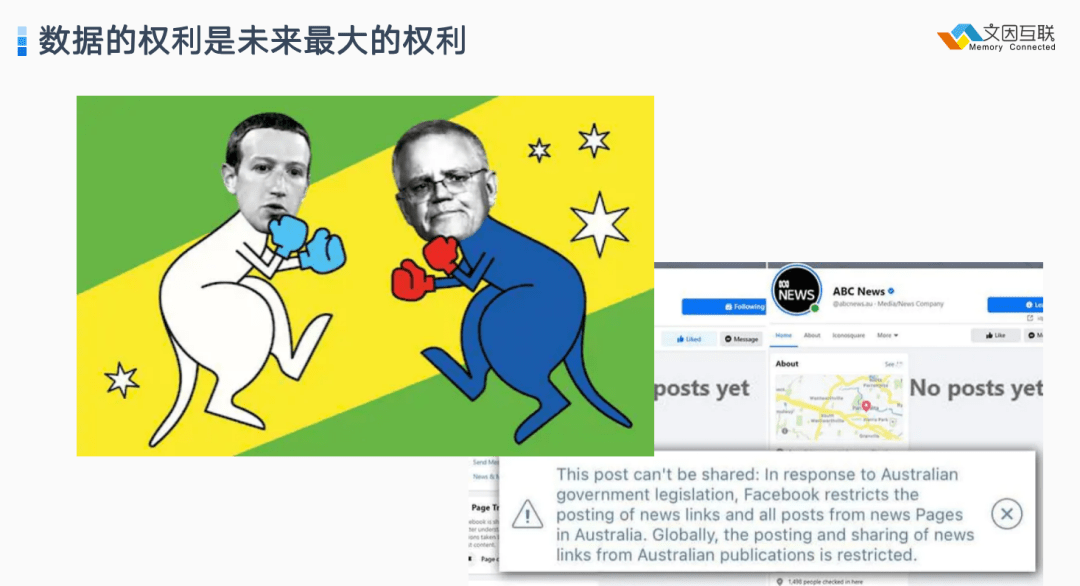
2005 年后 Tim Berners-Lee 感觉到 Web 走向一个错误的方向,开始进入到所谓的 Walled Garden 时代,比如 Facebook 、MySpace 、Linkedin 等社交媒体相互之间建立了数据壁垒。以前网页可以自由地向另外一个网站的网页建立链接,这样数据可以自由地连通在一起。但随着进入社交网络时代以及进入到移动互联网时代,大量数据被封闭在 APP 里,导致互联网变成一个个有高墙的诸侯国。
价值的封闭即是价值的丧失。所以 2009 年 Tim Berners-Lee 发表了一个很有名的 TED 演讲《 Raw data now 》(立即发布你的裸数据),演讲中提到如果让数据被这些大网站所垄断就会带来一些严重后果。但当时大多数人不能理解这句话。

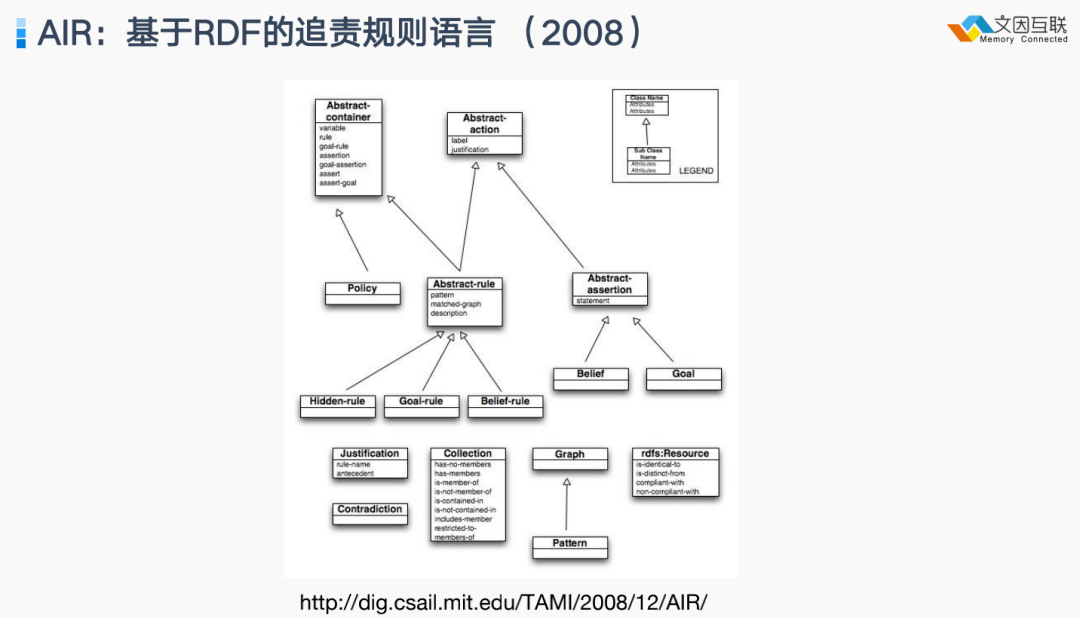
在 2010 年前后,我在 Tim 的实验室(MIT DIG 分布式信息系统实验室)工作,我们的主要工作就是如何打破 walled garden。有一部分工作在 provenance上,即信息溯源的问题,部分成果成为了 W3C 的一个标准PROV;还有一部分工作在inference web,本质上是研究如何建立类似后来的区块链那样的账本。TAMI(Transparent Accountable Datamining Initiative)项目研究了可追责的Web信息集成;此外还有 AIR(accountability in RDF)语言,类似于后来的智能合约语言,而且表达力更强。我们试图用这些技术来打破 Web 2.0的壁垒,这些技术后来演化为了今天的 Web 3.0 技术的一部分。
在 15 年前我们探索这些想法时,其实还不能完全理解这件事情的核心意义。但随着过去这十几年,随着大数据,尤其近年来数字资产的发展让我们逐渐理解到,数据的价值在于它是一种资产,甚至可以说是世界上最有价值、最有增长性的资产。当数据本身的权利和交互被限制时,也就是在限制整个社会财富的增长。所以就是为什么一定要打破这些墙,一定要让数据自由流通才能创造出更多财富。

前段时间 Facebook 发生一件事情——把澳大利亚整个国家的新闻都封掉了。在去年美国大选时也出现了美国总统的推特、Facebook 账号被社交媒体封掉的事情,也就是说社交媒体所拥有的权利甚至已经超越了传统的政府,我们怎样去制约它?未来如何保证这些数据的权力不被滥用?这是当前社会治理的很大问题。(P.S. 2022年5月推特被 Elon Musk 收购后解除了这个封锁)
老Web 3.0 : 语义网—— Web任务自动化
这些问题在 21 世纪的第一个十年时并没有被解决。在那个时代我们曾思考:Web 的下一代到底是什么?Web 3.0 是不是语义网(Semantic Web)?
Web 3.0这个词,最早来自 Tim Berners-Lee 2006 年在纽约时报的文章 “A 'more revolutionary' Web” 。2007年,W3C 的 CEO Steve Bratt 做过 “Web 3.0 Emerging” 的演讲。2009年1月,James Hendler 组织了 IEEE Computer 的特刊 “Web 3.0 Emerging” 。2009 年3月,在AAAI的春季研讨会上,我和丁力等人组织了一个 symposium,Social Semantic Web: Where Web 2.0 meets Web 3.0,探讨了新一代 Web 应该是什么样。
所以虽然今天 Web 3.0 已经被重新定义为以区块链为基础的一系列技术,但是在 2020 年以前,这个词是指语义网有关的技术。但是我们也可以看到,这两种路径的目的都是建立起分布式应用,只不过老的 Web 3.0 是从业务规则的建模(知识技术)来切入的,而新 Web 3.0 是从底层数据的分布式溯源(互信技术)来切入的。它们有统一的最终目标。

语义网和之后的知识图谱的本质是什么?那时有人认为语义网就是用 RDF 来发布数据,后来又认为语义网就是元数据等等,大家各种争论。作为一个应用派,我对于语义网的理解是:我们不应在乎结构化数据到底用 JSON 还是 Graph Database 等语言来表示,这些本质上是一样的。
核心在于,用这些数据来做什么? Web 的任务自动化才是语义网的核心本质。例如在各种订餐网站上订餐是一个很典型的任务自动化,但为了达到这点我们背后要做多少知识图谱的构造工作啊!必须要把所有的地理实体、餐馆实体、菜单实体(menu)都进行结构化,才可能有订单的任务自动化和任务的自动分发。

从这个角度来看今天的线上生活已经非常发达,我们完全可以认为经过 20 年的发展,当年语义网的愿景——生活自动化——已经初步实现。回来看 2001 年 Tim Berners-Lee 最有名的《Semantic Web》文章,它描绘了一个远程生活自动化(医疗场景)的愿景,在疫情后的今天可以看到文中大半内容已经实现,当年的科幻已变成现实。所以从这个角度来看语义网非常成功。
从另外一个角度来看语义网也是上一个世代的 DApp(分布式应用)。DApp 一词随着区块链技术被广为人知。但本质上来说语义网就是当年的 DApp ,我们构造了很多有趣的智能应用,例如semantic wiki。在那种构造范式中,代码可以自动的在不同应用间转移,因为代码本身就是数据,代码可以自动聚合,同一个数据可以完全脱离它原始的应用以不同的方式来呈现,这都是非常神奇的一种应用,但在 15 年前就已经有了。所以语义网的本质,从应用来说就是 一种构造分布式应用的方法。
语义网 = Web 任务自动化 & Web 分布式应用。这是我个人对语义网的两种理解。这和今天的 Web 3.0 是非常接近的。

但语义网在 2005 年、2006 年之后也进入了一个小低谷:变得过于复杂(整个协议栈有非常多的内容),所以大多数工程师不太能理解。下面这个是著名的“语义网层次蛋糕”,给出了2006年的语义网的技术栈。这个技术栈过于复杂,简化后为知识图谱技术继承。
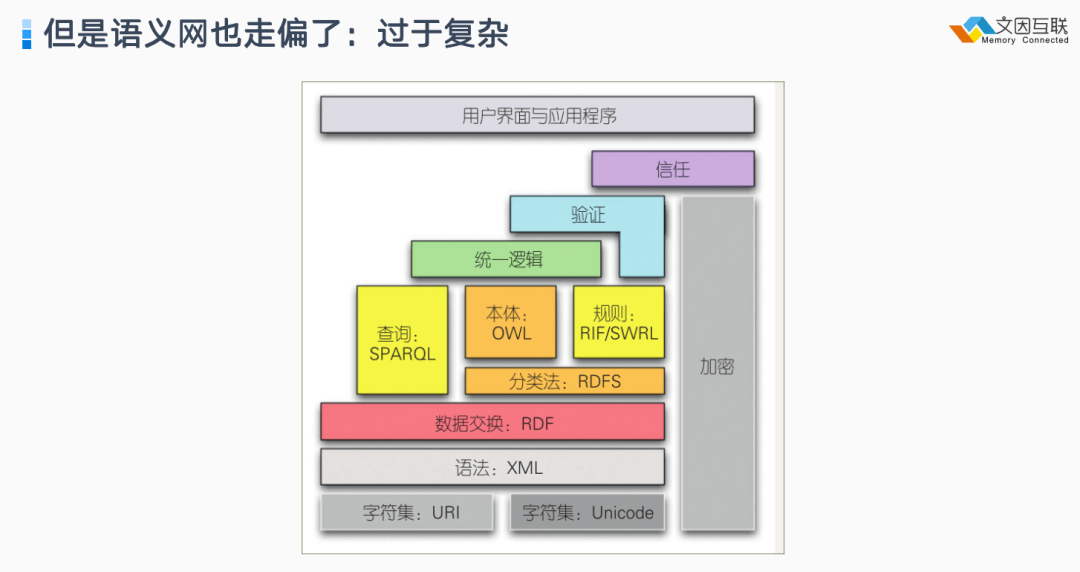
在 21 世纪的第二个十年,语义网技术被三种技术领域所继承。底层是 图谱技术也称为知识图谱,是对于数据层,比如说实体和关系如何进行数据库层面的建模、存储、查找;第二个领域是 知识技术,就是本体、规则、推理机、流程引擎,这部分过去十年里发展最缓慢但可以看到最近两三年有了蓬勃的发展;第三块是 互信技术,就是层次蛋糕模型右面的加密、验证、信任和统一逻辑部分。
当初我们做语义网时是不太理解的,语义网不就是逻辑语言的表现吗?为什么要加上 trust 和 proof 这些内容?到了今天就终于理解了,因为对于构造分布式应用,信任的互联是不可或缺的。
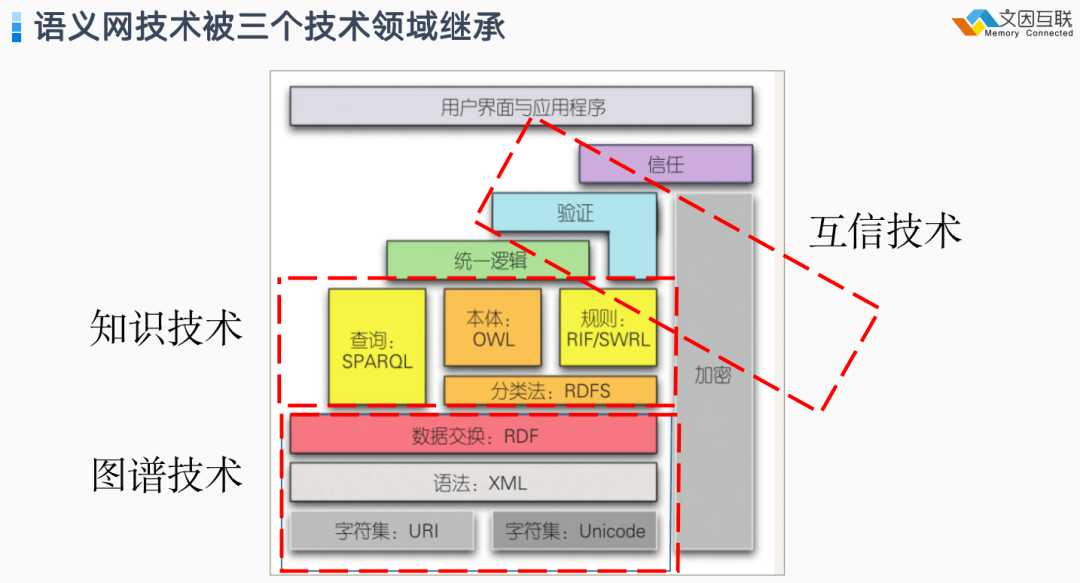
上面讲到语义网技术被知识技术、图谱技术和互信技术三种技术所继承,从另一个视角来看它也是知识技术的不同呈现。知识技术可以分为“产生知识的技术”和“转移知识的技术”。再进一步细分下,转移知识的技术又分为:“组织内转移知识”和“组织间转移知识”。组织内转移知识,是用各种各样的分发规则即可,例如 OWL 、RDF 、RuleML等。但在组织之间分享知识就会遇到组织间信任不足的问题,所以必须要引入一些新的技术叫“互信技术”。这就是今天我们所称的“Web 3.0”技术。
新Web 3.0 : 数字资产市场经济
在 Web 的 30 岁时,总结新时代的 Web 3.0 ,也就是未来十年 Web 会变成什么样子?在我看来,它会有几个核心特征:
第一个是货币将成为互联网的固有特征。现在提到互联网都说是大数据,但实际上这些数据本身是有价值的,而这种价值未来会成为可交换的各种各样的通证(Token),随着各种数字货币的进一步普及,价值本身将成为互联网的一种固有特征;
第二个是如今的互联网是一种中心化应用,我相信未来它会成为一种去中心化的应用,就是当年语义网的这些理想会进一步实现
第三个是数据资产权利和数字身份将成为一种核心的可以交换的实体。
这些特征最终将带来一种新的经济形态——“ 数字资产的市场经济”。

回到当年 Tim Berners-Lee 提到的一定要约束 Facebook 这种公司的行为,为什么要做这种事情?本质上来说就是由于这种权利的界定,才能够激发起一种数据的交换。前面提到价值的封闭即是价值的丧失,当我们能够打开这些价值并让这些价值自由地交换时,就是在促进经济的增长。
相信这也是 Tim Berners-Lee 过去 15年工作经验所总结出来的一个非常重要的结果。所以 数字资产的权利将催生全新的产业。我认为这是整个知识工程领域奋斗二三十年要去做这些事的原因。我们很多人在20多岁就开始做这些事,如今我们这一批人都近50岁了,过去20多年的时间中这些努力到底有什么意义?我相信意义就在这里。
正如财产的私有制促进了产业的分工,知识产权保护制度促进了知识的传播,数字资产权利将催生数字资产的市场经济。这又恰恰是 Web 内生的属性,因为 Web 的本质本来就是信息的市场经济。在 Web 1.0 时代实现了信息本身的互联,在 Web 2.0 时代实现了与现实市场经济的线上到线下(O2O)映射,到了 Web 3.0 时代则更进一步,将使 Web 具备市场交换的内生属性,而不再需要 O2O 过程。如果我们相信过去的市场经济极大提升了整个人类的福利,那数字的市场经济,会不会带来更大的经济增长呢?我坚信这一点。

2009年 David Siegel 出了一本书《The Power of the Semantic Web》,后来中文翻译成 《Web 3.0》 。虽然这本书已经过去十几年,但仍值得一读。他在书中提到一个概念 ——personal data locker,也就是每个人拥有自己的数据后,可以去交换这些数据,他把这个交换过程称为 “pull ”,也就是由机器、规则来自动执行的数字机器人。在 Web 3.0 这样一种视角下,就是自由的个人知识市场交易,这是人和机器协作的一个大规模网络。

在 2008 年有两种技术同时诞生,今天回过头来看并不是偶然的。一个是中本聪提出的区块链,另外一个是 Tim Berners-Lee 所提出的 AIR ,也就是基于 RDF 的可追责语言。这两者所要解决的问题都是类似的:我们如何在一个不可信的环境下通过难以篡改的账本或记录或推理,来实现一种可信的信息交换。所以这两种技术路线都是可行的,只是因为当时中本聪的想法更接地气,所以今天区块链技术更成功。
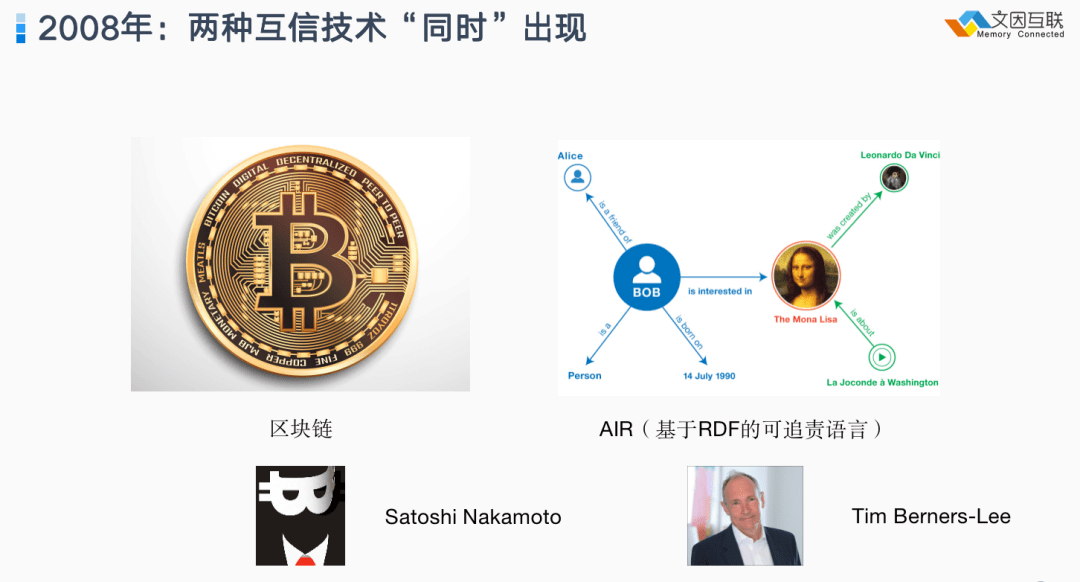
Accountability(可追责) 这种思想在十几年前提出,已经被数字货币和区块链领域很好的继承下来。它的原始思想和 Web 和市场经济如出一辙:我们不能事先禁止所有行为,但可以记录一些行为并且事后去进行追责;在反复发生的交易过程中,就可以让高质量的信息或者服务获得优势。追责分成很多个步骤,Accountability 有很多组件,例如如何去记录这些内容、如何去溯源这些行为,最终我们要通过正确的推理来发现做错事的人。
Web 3.0的本质就是 accountability。区块链这种账本也好,AIR 这种规则语言也好,都是为了界定权利,从而保障了大规模的交易的发生。这依然是为了 serendipity,依然是为了更大规模的信息市场经济。

Web 3.0 的 7 层技术栈
我们只需知道分布式信任技术不仅是区块链,还包括信任物的电子化、各种可追责性技术等,区块链只是其中之一,也包括各种开放调度系统(各种服务的协同技术),所以它是一个很大的技术堆栈。现在就来回顾一下过去十几年里有哪些互信技术以及带来了什么,把其中有代表性的讲一下。
其中一个是 2008 年所提出的 AIR 技术,也就是基于 RDF 的追责语言,或者说它是一种 policy language,去刻画我们如何能够以一个抽象的、对于每个人能做什么,以及我们如何去记录处理数据中间的每一步,当时称为“ provenance ”,这种 信息账本如何描述出来?所以 AIR 其实就是 RDF 或语义网时代的一种分布式账本和规则语言。
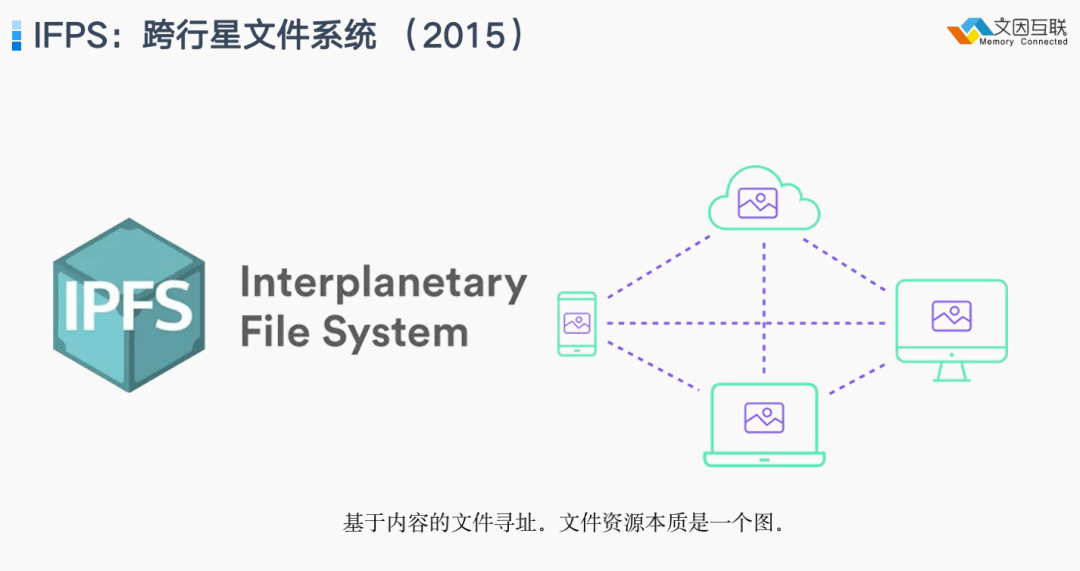
2015 年在存储层出现了一个新的技术—— IFPS ,经过六年的发展现在已经变得非常热门。它抛弃完全只用 URL 来进行内容互联的方法,实现了 基于内容的文件寻址,所以每一个文件在 IFPS 上是一个互联起来的图,图上每个节点都可能被重用,每个内容都有一个属于自己的哈希值,所以最终整个文档都有自己的一个哈希值,如果你熟悉 Git ,其实整个原理是非常类似。所以它的名称也非常野心勃勃叫“跨行星文件系统”,理论基础就是基于内容的寻址。
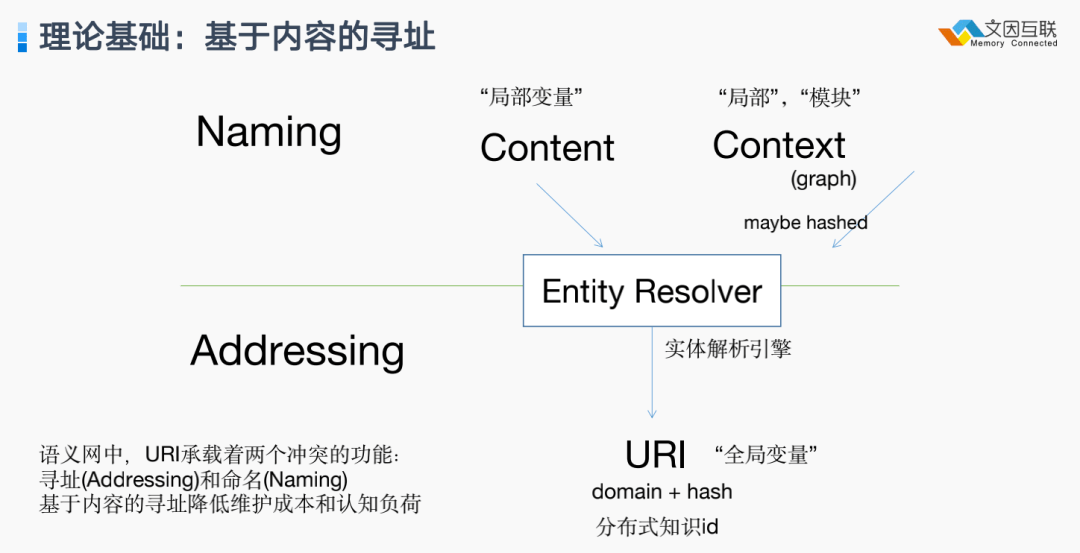
2015年,schema.org的作者 Guha(也是RDF发明者)写了一篇文章,讲述了如何能够通过描述或者内容来进行寻址。这里就讨论了传统的 URL 的两个不同角色:一个是命名(Naming),一个是寻址(Addressing)。这两个角色是相互冲突的。在 IFPS 里实现了 Guha 讲的一部分想法,就是把内容寻址和地址寻址统一在一起,这样既降低了维护成本也降低了使用者的认知负荷。
另外一个技术是 Solid 框架,一个分布式身份确认的框架。我们可以用身份证来做一个比喻。其实身份证号码是一种非常不安全的东西,你告诉某个人你的身份证号码或者社保号,那么它就存在被滥用的可能,那能否去改变这个现象?因为身份对我们来说是一种非常重要的资产。Solid 就是对这个问题的回答,也是Tim Berners-Lee 在2016年的发起的一个项目,它是要解决在开放的不可信的环境下如何进行身份认证的问题。另外 W3C有一个分布式数字身份的标准 Decentralized Identifiers (DIDs),也值得关注。

另外一个是2014 年开始发展的技术 NFT ,它是对数字资产进行一种确权的方法。
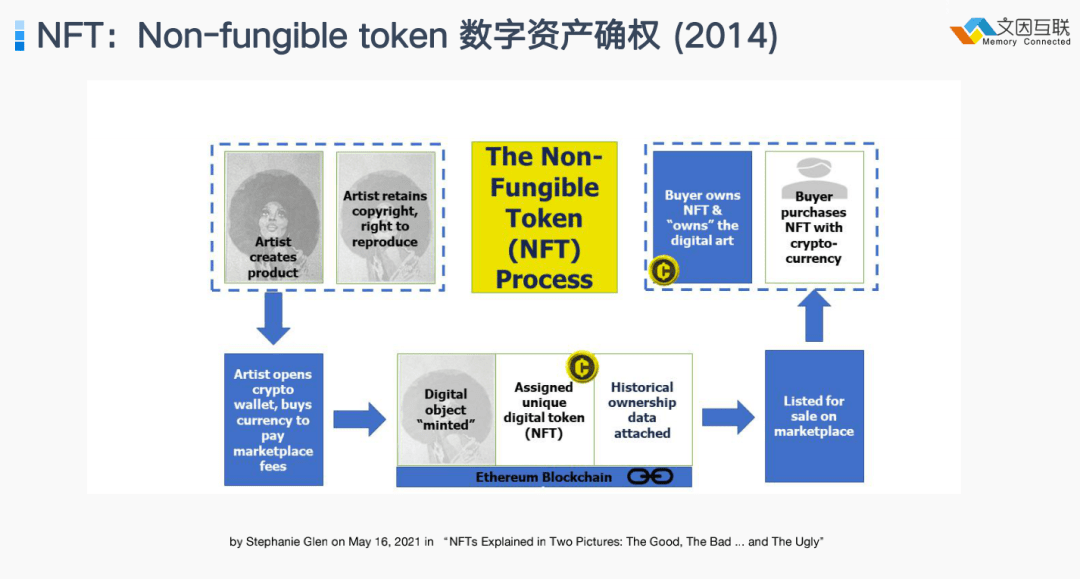
前两天出现一个新闻——两个星期前 Tim Berners-Lee 把 Web 最早的源代码打包成一个 NFT 卖了540万美元。在过去一年中 NFT 有了非常巨大的发展,现在已经变成一个数十亿美元甚至可能已经达到上百亿美元的一个巨大市场。尽管这里面有很大的泡沫,但是我相信经过几年的泡沫沉淀后,有持久价值的应用场景会浮现出来。

另外一个技术叫 Uniswap 。当我看到 Uniswap 时眼前一亮。我们这些做推理机的人终于找到一个特别好的落地场景。Uniswap 是一个自动清算协议。当 Token 交易时,需要一种如何让它们更好的去进行交换的清算过程,就是一大堆规则的执行。我们现在在网上所看到的交易还是比较简单的,但随着未来 Token 的多元化,尤其让数字资产的保护成为一种普适性内生存在时,我们就需要一种更加复杂的清算过程。我相信未来这种价值交换协议会和操作系统(OS)一样复杂,而这个东西的底层可能是我们 第一次需要一个大规模的推理机在下面来起作用。

最近我在做一项工作,可以称为“ AI Contract Lang(AICL)”,它是对于 Smart contract(智能合约)的一个发展,因为 Smart contract 并没有智能在里面,如果把底层的运作运行在推理机上,那么就可以给未来的数字资产交换引擎带来非常多新的智能性,包括投资、信贷、金融监管、供应链、数字货币等,可以看到有非常多的应用场景,我列举了一些,但还有更多有待探索,这是一个非常具有发展潜力的领域。
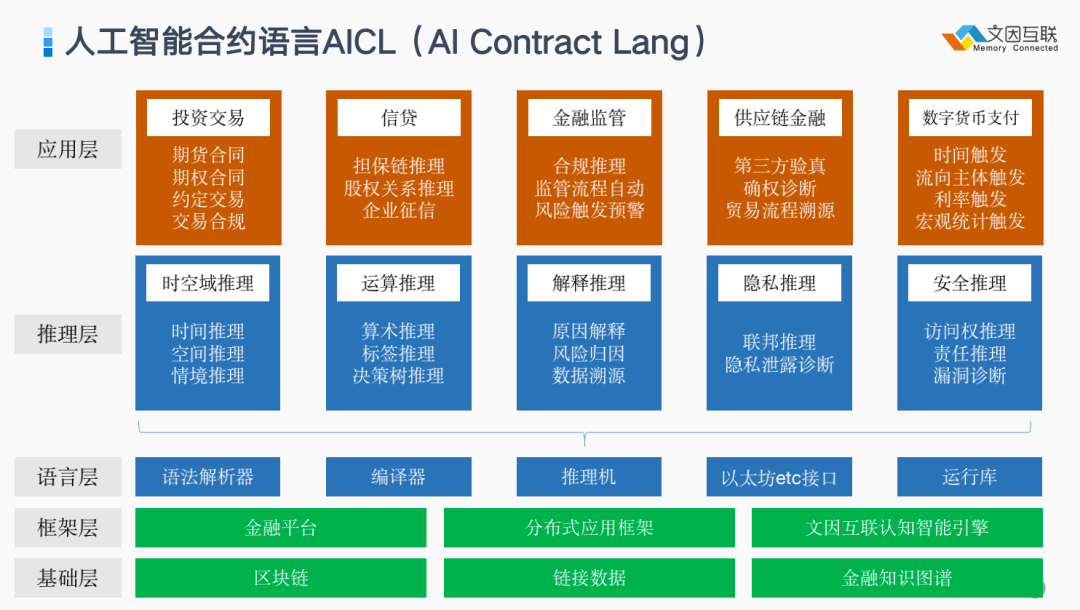
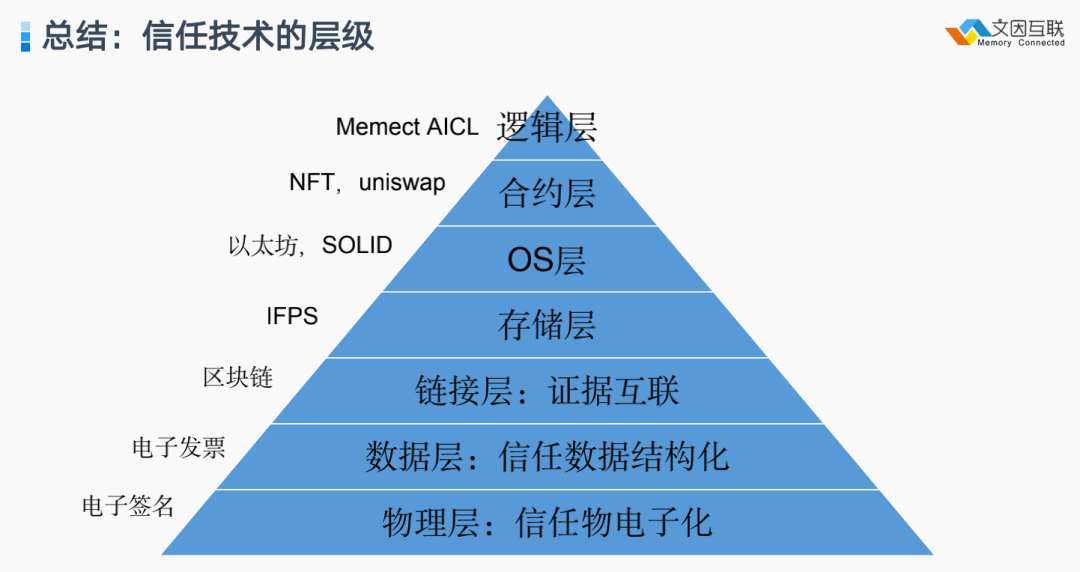
总结下来,上面提到语义技术被分解为三个部分继续发展,其中一部分叫互信技术。我简单的把互信技术从下到上分为七层,把上面提到的几种协议分别列在上面,分别是1)物理层,2)数据层;3)链接层;4)存储层;5)OS层(操作系统或者操作原语层);6)合约层;7)逻辑层。当然这个领域一日千里,这里挂一漏万,一定有很多进展没有考虑进来,要随时更新。
所以,有结构化数据本身并不是核心目的,让这些结构化数据(也就是所谓的元数据)能够帮助我们在网上让数据更好地进行交换才是目的。尤其是今天在组织之间、个人之间可以进行数据交换,进行资产确权,使我们过去20年在语义网里做的所有事情,今天在一个新的价值互联网上面都可以再次应用起来,所有的努力都没有被浪费,这是让我非常兴奋的一件事情。
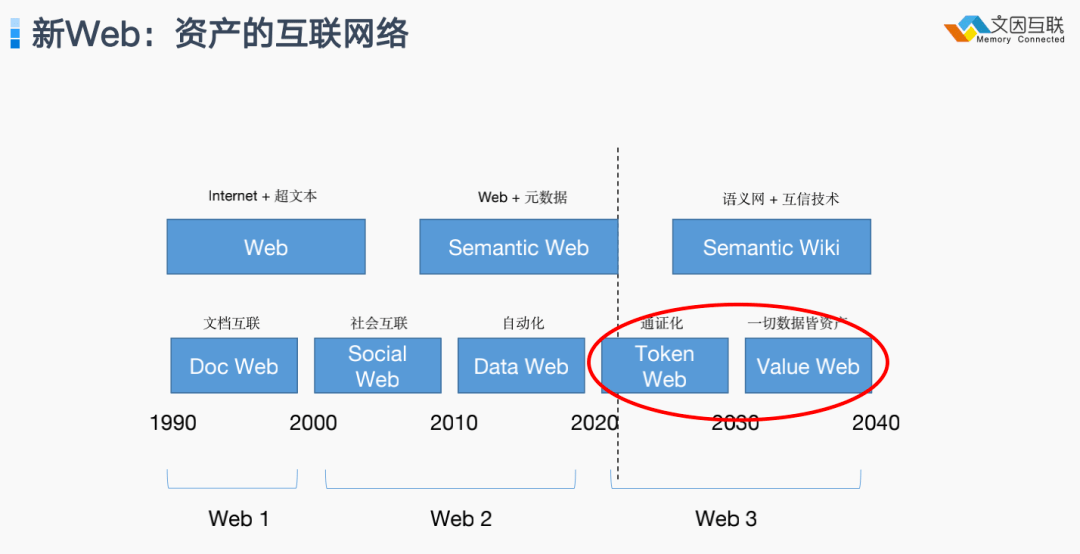
所以在未来的二、三十年里我相信万维网将真正进入第三个年代,就是 Web3 的年代,也就是 价值互联网的时代。我预期它又分为两步:第一步是如何把所有的 数字资产通证化的过程,我称为token web;第二步是如何让这些通证数据能够相互自由交换的过程,我称为value web,也就是数字资产的市场经济。整个过程可能还需要20年的时间发展成熟。
我相信这些技术会带来一种全新的经济形态,它的商业价值可能比上一个时代的互联网还要更大 10 倍甚至 100 倍。上一个时代的互联网,终究还是基于线下实体价值的交换,但是数字资产化所带来的价值互联,可能会创建远远超越线下实体的经济规模。我认为 这是当前这个星球上发生的最大的一件事情,超过任何战争、贸易纷争、恩怨。
 |
 |
 |
 |
 |
 |
 |
 |
| 感动 | 同情 | 无聊 | 愤怒 | 搞笑 | 难过 | 高兴 | 路过 |
相关文章
-
没有相关内容